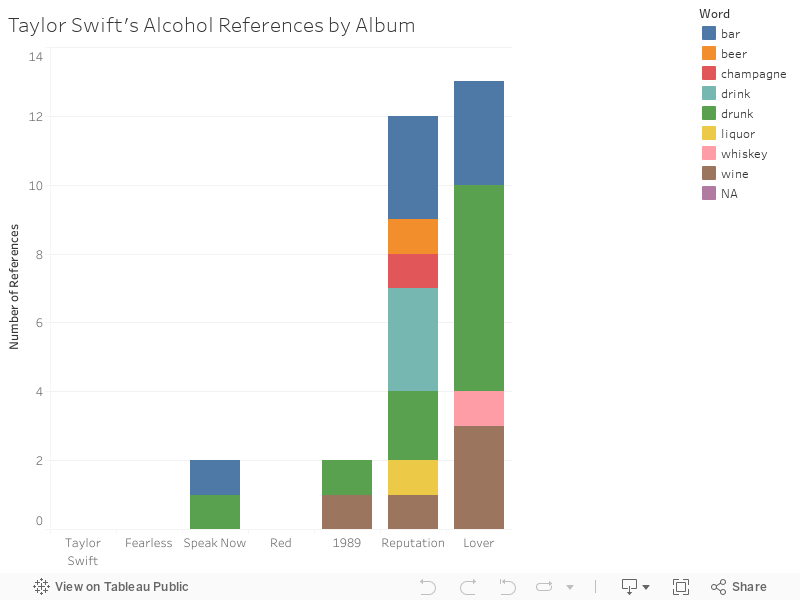
Update:
A few people reached out asking me to re-run this analysis for Ms. Swift’s latest album, Lover. I did and was somewhat surprised to see that the alcohol references weren’t a passing phase.
I followed the same methodology as I did for the below, but this time put the data into Tableau Public for interactivity.
If you like this sort of thing, sign up below and I’ll email you when I write something new.
I listened to Taylor Swift’s new album and couldn’t help but notice that she talks about alcohol a lot.
I liked the album, I just thought it was goofy and emblematic of her persona change from sweet country popstar to dark, revenge-driven mogul.
I wanted to visualize the change in alcohol-related content in Swift’s albums. I am Using Josiah Parry’s geniusR package to scrape Taylor Swift lyrics. I have worked on lyric scraping before and it can be a pain, so I’m really excited about this package.
I’ll then use tidytext to analyse them.
devtools::install_github("josiahparry/geniusR") # the geniusR package isn't on CRAN, so load with devtools
library(geniusR)
library(tidyverse)
library(tidytext)
library(rvest)
library(readr)
library(lubridate)
library(igraph)
library(ggraph)
library(readr)I want to get all of Swift’s lyrics from each album. There isn’t a function do this in geniusR, and looking at the Genius website, it makes sense why: to show all the albums for an artist, you have to click through a link on the artist’s page; this opens an interactive box that doesn’t have its own URL. This would make it tougher to scrape.
To deal with this, I’m going to scrape Swift’s album titles from Wikipedia. She has a Wikipedia page for her discography that I found by googling “Taylor Swift Albums.” It has a table of his albums that should be easy to scrape with RVest.
I am also going to scrape the dates, which are formatted sort of messily (they are bullet points within cells in the table). It will add a little work to scrape and clean them but they’ll be useful for analyzing change in lyrics / sentiment over time.
If you’re not familiar with RVest, there’s a great tutorial here. I also use the SelectorGadget tool to find the proper CSS element for the html_nodes() function; it’s incredibly useful.
Scraping wikipedia for album titles and dates
wiki_url <- "https://en.wikipedia.org/wiki/Taylor_Swift_discography"
# pulling album titles
alb_titles <- html_session(wiki_url) %>%
html_nodes(".plainrowheaders:nth-child(11) tr~ tr+ tr th") %>% # found the html node using SelectorGadget
html_text() %>%
data_frame()
names(alb_titles) <- c("title")
# getting release dates
alb_dates <- html_session(wiki_url) %>%
html_nodes(".plainrowheaders:nth-child(11) th+ td li:nth-child(1)") %>%
# again, found the right node by using SelectorGadget
html_text() %>%
data_frame()
names(alb_dates) <- c("date")
# combining the two data frames
albums <- cbind(alb_titles, alb_dates)
head(albums)This looks good, but I’ll have to remove the extra text in the date column in order to convert them to dates and analyze them as such.
Cleaning dates
albums$date <- gsub("Released: ", "", albums$date)
albums# make sure leading and trailing spaces are deleted
albums$date <- trimws(albums$date)
albumsLooks good. Now we’ll cast the dates as dates. This is a very helpful site for datetime formatting, that’s where I got the “%B %d, %Y”
albums$date <- as.Date(albums$date, "%B %d, %Y")
write_csv(albums, "taylor_swift_albums.csv")Now that we have every album, we want to get the lyrics for each album. I am doing it with a for loop, even though I should probably do it with apply. I have found apply to be a lot harder to put to use though, if you have any suggestions on how to use it here please let me know.
Getting lyrics
taylor_lyr <- data_frame()
for(i in 1:nrow(albums)){
current_lyr <- genius_album("Taylor Swift", albums$title[i]) %>%
mutate(album = albums$title[i])
taylor_lyr <- rbind(taylor_lyr, current_lyr)
message(albums$title[i])
}Joining this with albums to add the dates
taylor_lyr <- taylor_lyr %>%
inner_join(albums, by = c("album" = "title"))
write_csv(taylor_lyr, "taylor_lyr.csv")Great! Now we have all the lyrics to all of their albums and their dates. We can start analyzing this.
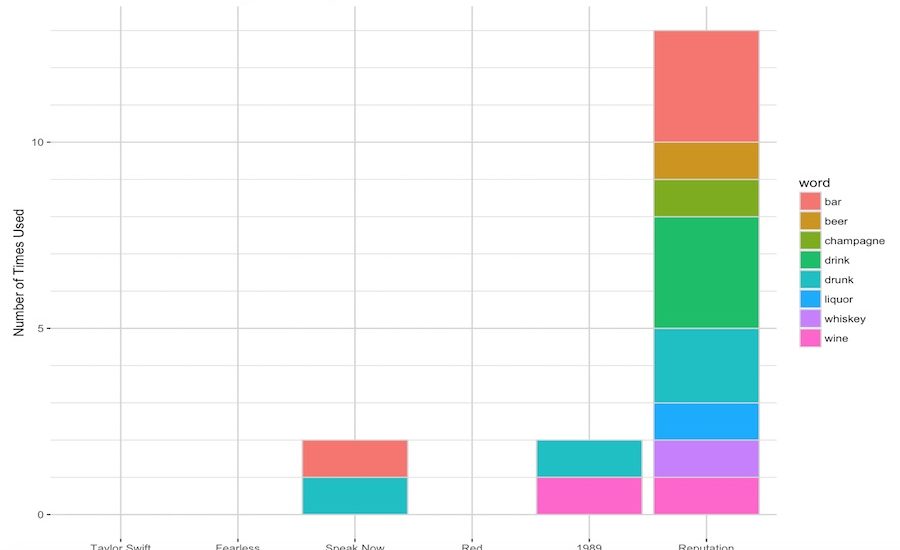
Alcohol-Related Content
I am going to make a dictionary of alcohol-related words and see how often they appear in each album.
word <- c("beer", "wine", "alcohol", "drink", "drunk", "champagne", "bar", "whiskey", "liquor")
alcohol_words <- data_frame(word)
# importing albums dataset
albums <- read_csv("~/taylor_swift_albums.csv")## Parsed with column specification:
## cols(
## title = col_character(),
## date = col_date(format = "")
## )Now will unnest words from Taylor’s lyrics and join them with the alcohol words
taylor_lyr <- read_csv("~/RProjects/taylor_lyr.csv")## Parsed with column specification:
## cols(
## title = col_character(),
## track_n = col_integer(),
## text = col_character(),
## album = col_character(),
## date = col_date(format = "")
## )taylor_words <- taylor_lyr %>%
unnest_tokens(word, text)
taylor_words %>%
inner_join(alcohol_words) %>%
group_by(album, date, word) %>%
summarise(n = n()) %>%
right_join(albums) %>%
replace_na(list(word = NA, n = 0)) %>%
ggplot(aes(x = reorder(title, date), y = n, fill = word)) +
scale_y_continuous(minor_breaks = 1:16) +
geom_col(colour = "lightgrey") +
labs(y = "Number of Times Used",
x = "Album",
title = "Alcohol References in Taylor Swift Lyrics, by Album") +
theme(panel.background = element_rect(fill = "white"),
panel.grid.major = element_line(colour = "lightgrey"),
panel.grid.minor = element_line(colour = "lightgrey"))## Joining, by = "word"## Joining, by = "date" Sentiment analysis and bigrams
Sentiment analysis and bigrams
Happiest and saddest songs. Taylor Swift’s songs are much happier generally than the Arctic Monkeys’ and Vampire Weekend’s songs, which I analysed recently:
Sentiment analysis on Arctic Monkeys and Vampire Weekend lyrics using @JosiahParry ‘s great geniusR package to scrape lyrics.
Lexicon-based sentiment analysis misses a lot with these bands; some songs I think of as quite happy ranked as sad and vice versa pic.twitter.com/bpT6jOBQNE
— Joe Hovde (@Jhovde2121) April 2, 2018
# writing a function to find the most positive and negative songs
sentimental_songs <- function(df){
df %>%
unnest_tokens(word, text) %>%
group_by(title) %>%
inner_join(get_sentiments("afinn")) %>%
summarise(sent = mean(score), track = mean(track_n)) %>%
filter(abs(sent) > 1) %>%
ggplot(aes(x = reorder(title, sent), y = sent)) +
geom_col(aes(fill = ifelse(sent > 0, "blue", "red"))) +
coord_flip() +
theme(legend.position = "none",
panel.background = element_rect(fill = "white"),
panel.grid.major = element_line(color = "white"),
panel.grid.minor = element_line(color = "white"),
panel.border = element_rect(color = "lightgrey", fill = NA)) +
labs(x = "",
y = "Song Sentiment (The More Positive, the Happier the Song")
}
sentimental_songs(taylor_lyr) + labs(title = "Taylor Swift's Happiest and Saddest Songs")## Joining, by = "word"
I don’t think this lexicon-based sentiment analysis does a very good job of depicting the sentiment of songs; it misses too much nuance and the actual music is such an important part of whether a song comes across as happy or sad.
Visualizing the bigrams in her lyrics
I use the really useful visualize_bigrams() function from tidytextmining.
count_bigrams <- function(dataset) {
dataset %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
count(word1, word2, sort = TRUE)
}
visualize_bigrams <- function(bigrams) {
set.seed(2016)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
bigrams %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, arrow = a) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()
}Apply the functions to her lyrics:
bigrams <- count_bigrams(taylor_lyr)
bigrams %>%
filter(n > 5) %>% # only bigrams with 5 or more occurences
visualize_bigrams()
This gives a nice graph of th most common bigrams. There are a lot of bigrams that consist of single words, for example “hate” in the top right corner. It’s easy to think about where these come from; “Shake it Off” features the lyrics “The haters gonna hate, hate, hate, hate, hate” and so this will be a relatively common bigram.
Thanks for reading!
Let me know if you’d like the data; email me at joe at this website or contact me on twitter.
If you like this sort of thing, sign up below and I’ll email you when I write a new post.