
“The Brooklyn of ______” is a goofy but useful shorthand. If you are in an unfamiliar city and you are in dire need of a craft cocktail or a vintage store or a wall mural you can use this phrase to identify a neighborhood where you will feel comfortable.
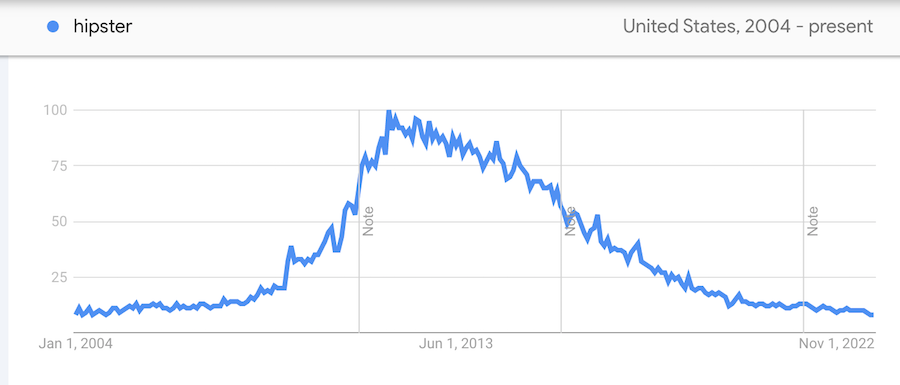
The brooklynization of every city is not a novel concept and several people wrote about it during the golden age of millennial hipsterism in the 2010s (RIP, see below chart from Google Trends).
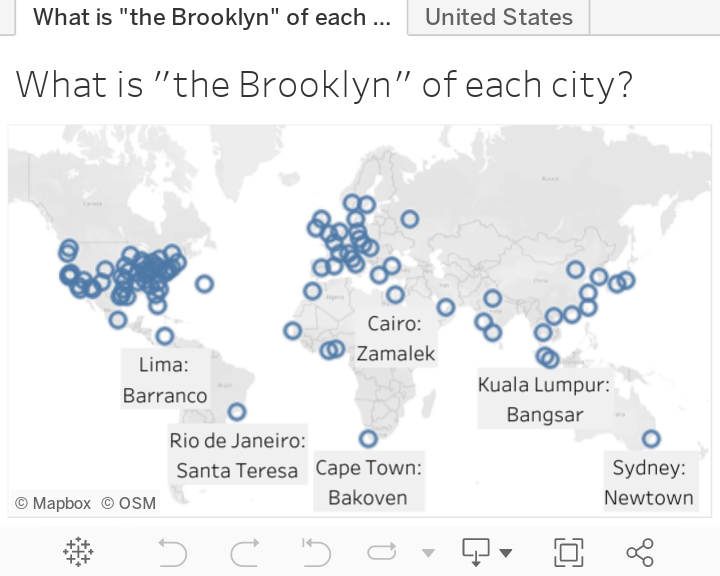
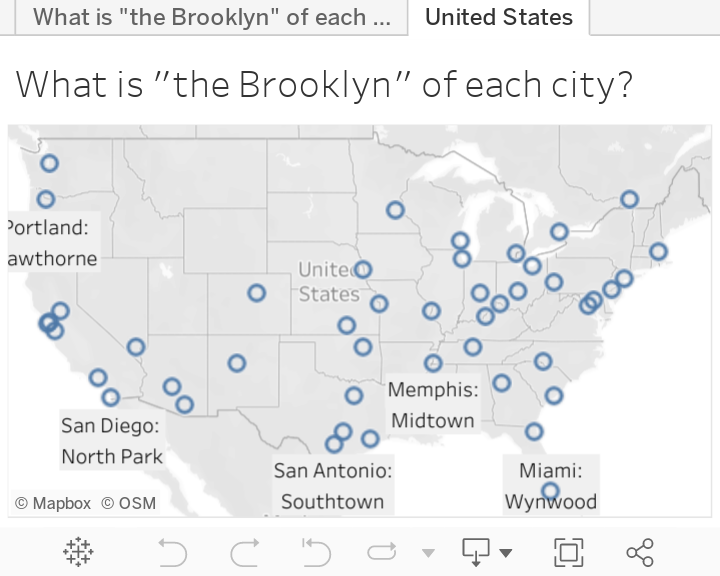
I wanted to see “the Brooklyn” of lots of cities at once and so I used the OpenAI API to query “what is the Brooklyn of ______?” for about 90 different world cities. I spot-checked its accuracy using the cities that I know well and it was impressively accurate (for example Over-the-Rhine in Cincinnati, the cover photo of this post, is close to my heart and defines the category for me).
You can check out the spreadsheet of neigborhoods and cities here, or see what you think for both the world and the US in the maps below. I have spent time in about 25 of them, which gives me very mixed emotions. If you’ve been to more than 45 let me know on twitter, I can only assume your body is now made mostly of cold brew and exposed brick and I’d like to study you.
A note on using AI for stuff like this
I would not have done this analysis without easy access to LLMs that made it dead simple. Even one year ago, if I had this idea, I would have had to come up with some method of scraping Reddit posts and counting the mentions of different neighborhoods in each city along with “Brooklyn”, or maybe hacked together some way to google “Brooklyn of ______” and parse the top results. These would have taken hours and required a reasonable amount of technical skill.
The OpenAI API makes this process ~100x easier. The technical difficulty was trivial, ChatGPT wrote most of the Python script and the LLM did all of the work of parsing all of the information on the internet to come up with a neighborhood for each city. It took about 20 minutes, and the main limiter is that Tableau and Google Sheets don’t have AI tightly integrated so I needed to do some manual work there. I expect that sort of implementation difficulty will be solved in the next few years and this will be even easier.
On the one hand, this is cool because it enables me to do more interesting things that I wouldn’t have the time or ability to do without this technology. On the other hand, it worries me on a few levels:
- It makes the “hard skills” that I thought were a defensible career asset trivial. Anyone with this idea and a very baseline knowledge of the necessary tools could have done this, and this will only get easier over time. It leaves me wondering what it is worth me being paid for.
- It feels weird that the LLM was trained on the work of humans, some of them paid journalists like the articles I linked to above, and some of them just people posting stuff on the internet. I don’t feel morally bad about it in this case because I’m not profiting from this but using the work of humans without attribution feels like cheating in some way.
I have gotten a few more ideas for projects that would not have been possible prior to the wide availability of LLMs. Mostly that is because the difficulty of gathering data would have been prohibitive and now it is not. I’m excited by this but I expect to continue to grapple with the above issues. If you have any thoughts on this please email me at joe @ this website.
Thanks for reading! If you enjoy this sort of thing, you might like this article I wrote about Blank Street Coffee (a commodified brooklyn coffee shop).
Sign up below and I’ll email you when I write something new: